Solving partial differential equations (PDEs) on shapes underpins many shape analysis and engineering tasks; yet, prevailing PDE solvers operate on polygonal/triangle meshes while modern 3D assets increasingly live as neural representations. This mismatch leaves no suitable method to solve surface PDEs directly within the neural domain, forcing explicit mesh extraction or per-instance residual training, preventing end-to-end workflows. We present a novel, mesh-free formulation that learns a local update operator conditioned on neural (local) shape attributes, enabling surface PDEs to be solved directly where the (neural) data lives. The operator integrates naturally with prevalent neural surface representations, is trained once on a single representative shape, and generalizes across shape and topology variations, enabling accurate, fast inference without explicit meshing or per-instance optimization while preserving differentiability. Across analytic benchmarks (heat equation and Poisson solve on sphere) and real neural assets across different representations, our method slightly outperforms CPM while remaining reasonably close to FEM, and, to our knowledge, delivers the first end-to-end pipeline that solves surface PDEs on both neural and classical surface representations.
SAGE: Structure-Aware Generative Video Transitions between Diverse Clips
Video transitions aim to synthesize intermediate frames between two clips, but naive approaches such as linear blending introduce artifacts that limit professional use or break temporal coherence. Traditional techniques (cross-fades, morphing, frame interpolation) and recent generative inbetweening methods can produce high-quality plausible intermediates, but they struggle with bridging diverse clips involving large temporal gaps or significant semantic differences, leaving a gap for content-aware and visually coherent transitions. We address this challenge by drawing on artistic workflows, distilling strategies such as aligning silhouettes and interpolating salient features to preserve structure and perceptual continuity. Building on this, we propose SAGE (Structure-Aware Generative vidEo transitions) as a zeroshot approach that combines structural guidance, provided via line maps and motion flow, with generative synthesis, enabling smooth, semantically consistent transitions without fine-tuning. Extensive experiments and comparison with current alternatives, namely [FILM, TVG, DiffMorpher, VACE, GI], demonstrate that SAGE outperforms both classical and generative baselines on quantitative metrics and user studies for producing transitions between diverse clips. Code to be released on acceptance.
B-repLer: Semantic B-rep Latent Editor using Large Language Models
Yilin Liu , Niladri Shekhar Dutt , Changjian Li , and Niloy J. Mitra
Multimodal large language models (mLLMs), trained in a mixed modal setting as a universal model, have been shown to compete with or even outperform many specialized algorithms for imaging and graphics tasks. As demonstrated across many applications, mLLMs’ ability to jointly process image and text data makes them suitable for zero-shot applications or efficient fine-tuning towards specialized tasks. However, they have had limited success in 3D analysis and editing tasks. This is due to both the lack of suitable (annotated) 3D data as well as the idiosyncrasies of 3D representations. In this paper, we investigate whether mLLMs can be adapted to support high-level editing of Boundary Representation (B-rep) CAD objects. B-reps remain the industry-standard for precisely encoding engineering objects, but are challenging as the representation is fragile (i.e. can easily lead to invalid CAD objects) and no publicly available data source exists with semantically-annotated B-reps or CAD construction history. We present B-repLer as a finetuned mLLM that can understand text prompts and make semantic edits on given B-Reps to produce valid outputs. We enable this via a novel multimodal architecture, specifically designed to handle B-rep models, and demonstrate how existing CAD tools, in conjunction with mLLMs, can be used to automatically generate the required reasoning dataset, without relying on external annotations. We extensively evaluate B-repLer and demonstrate several text-based B-rep edits of various complexity, which were not previously possible.
AutoBrep: Autoregressive B-Rep Generation with Unified Topology and Geometry
Xiang Xu , Pradeep Kumar Jayaraman , Joseph G. Lambourne , Yilin Liu , Durvesh Malpure , and Pete Meltzer
AutoBrep is a decoder-only Transformer model that autoregressively generates B-Rep geometry and topology tokens following a BFS order of the B-Rep topology graph. Geometric information is tokenized as bounding boxes paired with encoded UV-grid shape codes. Topological structure is represented via a special face identifier that maps face–edge adjacencies into reference tokens.
HoLa: B-Rep Generation using a Holistic Latent Representation
Yilin Liu , Duoteng Xu , Xingyao Yu , Xiang Xu , Daniel Cohen-Or , Hao Zhang , and Hui Huang
We introduce a novel method for acquiring boundary representations (B-Reps) of 3D CAD models which involves a two-step process: it first applies a spatial partitioning, referred to as the “split“, followed by a “fit“ operation to derive a single primitive within each partition. Specifically, our partitioning aims to produce the classical Voronoi diagram of the set of ground-truth (GT) B-Rep primitives. In contrast to prior B-Rep constructions which were bottom-up, either via direct primitive fitting or point clustering, our Split-and-Fit approach is top-down and structure-aware, since a Voronoi partition explicitly reveals both the number of and the connections between the primitives. We design a neural network to predict the Voronoi diagram from an input point cloud or distance field via a binary classification. We show that our network, coined NVD-Net for neural Voronoi diagrams, can effectively learn Voronoi partitions for CAD models from training data and exhibits superior generalization capabilities. Extensive experiments and evaluation demonstrate that the resulting B-Reps, consisting of parametric surfaces, curves, and vertices, are more plausible than those obtained by existing alternatives, with significant improvements in reconstruction quality. Code will be released on https://github.com/yilinliu77/NVDNet.
CLR-Wire: Towards Continuous Latent Representations for 3D Curve Wireframe Generation
Xueqi Ma , Yilin Liu , Tianlong Gao , Qirui Huang , and Hui Huang
We introduce CLR-Wire, a novel framework for 3D curve-based wireframe generation that integrates geometry and topology into a unified Continuous Latent Representation. Unlike conventional methods that decouple vertices, edges, and faces, CLR-Wire encodes curves as Neural Parametric Curves along with their topological connectivity into a continuous and fixed-length latent space using an attention-driven variational autoencoder (VAE). This unified approach facilitates joint learning and generation of both geometry and topology. To generate wireframes, we employ a flow matching model to progressively map Gaussian noise to these latents, which are subsequently decoded into complete 3D wireframes. Our method provides fine-grained modeling of complex shapes and irregular topologies, and supports both unconditional generation and generation conditioned on point cloud or image inputs. Experimental results demonstrate that, compared with state-of-the-art generative approaches, our method achieves substantial improvements in accuracy, novelty, and diversity, offering an efficient and comprehensive solution for CAD design, geometric reconstruction, and 3D content creation.
Generating 3D House Wireframes with Semantics
Xueqi Ma , Yilin Liu , Wenjun Zhou , Ruowei Wang , and Hui Huang
We present a new approach for generating 3D house wireframes with semantic enrichment using an autoregressive model. Unlike conventional generative models that independently process vertices, edges, and faces, our approach employs a unified wire-based representation for improved coherence in learning 3D wireframe structures. By re-ordering wire sequences based on semantic meanings, we facilitate seamless semantic integration during sequence generation. Our two-phase technique merges a graph-based autoencoder with a transformer-based decoder to learn latent geometric tokens and generate semantic-aware wireframes. Through iterative prediction and decoding during inference, our model produces detailed wireframes that can be easily segmented into distinct components, such as walls, roofs, and rooms, reflecting the semantic essence of the shape. Empirical results on a comprehensive house dataset validate the superior accuracy, novelty, and semantic fidelity of our model compared to existing generative models. More results and details can be found on https://vcc.tech/research/2024/3DWire.
Split-and-Fit: Learning B-Reps via Structure-Aware Voronoi Partitioning
Yilin Liu , Jiale Chen , Shanshan Pan , Daniel Cohen-Or , Hao Zhang , and Hui Huang
We introduce a novel method for acquiring boundary representations (B-Reps) of 3D CAD models which involves a two-step process: it first applies a spatial partitioning, referred to as the “split“, followed by a “fit“ operation to derive a single primitive within each partition. Specifically, our partitioning aims to produce the classical Voronoi diagram of the set of ground-truth (GT) B-Rep primitives. In contrast to prior B-Rep constructions which were bottom-up, either via direct primitive fitting or point clustering, our Split-and-Fit approach is top-down and structure-aware, since a Voronoi partition explicitly reveals both the number of and the connections between the primitives. We design a neural network to predict the Voronoi diagram from an input point cloud or distance field via a binary classification. We show that our network, coined NVD-Net for neural Voronoi diagrams, can effectively learn Voronoi partitions for CAD models from training data and exhibits superior generalization capabilities. Extensive experiments and evaluation demonstrate that the resulting B-Reps, consisting of parametric surfaces, curves, and vertices, are more plausible than those obtained by existing alternatives, with significant improvements in reconstruction quality. Code will be released on https://github.com/yilinliu77/NVDNet.
Learning Reconstructability for Drone Aerial Path Planning
Yilin Liu , Liqiang Lin , Yue Hu , Ke Xie , Chi-Wing Fu , Hao Zhang , and Hui Huang
ACM Trans. on Graphics (Proc. of SIGGRAPH Asia), 2022
We introduce the first learning-based reconstructability predictor to improve view and path planning for large-scale 3D urban scene acquisition using unmanned drones. In contrast to previous heuristic approaches, our method learns a model that explicitly predicts how well a 3D urban scene will be reconstructed from a set of viewpoints. To make such a model trainable and simultaneously applicable to drone path planning, we simulate the proxy-based 3D scene reconstruction during training to set up the prediction. Specifically, the neural network we design is trained to predict the scene reconstructability as a function of the proxy geometry, a set of viewpoints, and optionally a series of scene images acquired in flight. To reconstruct a new urban scene, we first build the 3D scene proxy, then rely on the predicted reconstruction quality and uncertainty measures by our network, based off of the proxy geometry, to guide the drone path planning. We demonstrate that our data-driven reconstructability predictions are more closely correlated to the true reconstruction quality than prior heuristic measures. Further, our learned predictor can be easily integrated into existing path planners to yield improvements. Finally, we devise a new iterative view planning framework, based on the learned reconstructability, and show superior performance of the new planner when reconstructing both synthetic and real scenes.
Capturing, Reconstructing, and Simulating: the UrbanScene3D Dataset
Liqiang Lin , Yilin Liu , Yue Hu , Xingguang Yan , Ke Xie , and Hui Huang
We present UrbanScene3D, a large-scale data platform for research of urban scene perception and reconstruction. UrbanScene3D contains over 128k high-resolution images covering 16 scenes including large-scale real urban regions and synthetic cities with 136 km^2 area in total. The dataset also contains high-precision LiDAR scans and hundreds of image sets with different observation patterns, which provide a comprehensive benchmark to design and evaluate aerial path planning and 3D reconstruction algorithms. In addition, the dataset, which is built on Unreal Engine and Airsim simulator together with the manually annotated unique instance label for each building in the dataset, enables the generation of all kinds of data, e.g., 2D depth maps, 2D/3D bounding boxes, and 3D point cloud/mesh segmentations, etc. The simulator with physical engine and lighting system not only produce variety of data but also enable users to simulate cars or drones in the proposed urban environment for future research.
Aerial Path Planning for Online Real-Time Exploration and Offline High-Quality Reconstruction of Large-Scale Urban Scenes
Yilin Liu , Ruiqi Cui , Ke Xie , Minglun Gong , and Hui Huang
ACM Trans. on Graphics (Proc. of SIGGRAPH Asia), 2021
Existing approaches have shown that, through carefully planning flight trajectories, images captured by Unmanned Aerial Vehicles (UAVs) can be used to reconstruct high-quality 3D models for real environments. These approaches greatly simplify and cut the cost of large-scale urban scene reconstruction. However, to properly capture height discontinuities in urban scenes, all state-of-the-art methods require prior knowledge on scene geometry and hence, additional prepossessing steps are needed before performing the actual image acquisition flights. To address this limitation and to make urban modeling techniques even more accessible, we present a real-time explore-and-reconstruct planning algorithm that does not require any prior knowledge for the scenes. Using only captured 2D images, we estimate 3D bounding boxes for buildings on-the-fly and use them to guide online path planning for both scene exploration and building observation. Experimental results demonstrate that the aerial paths planned by our algorithm in realtime for unknown environments support reconstructing 3D models with comparable qualities and lead to shorter flight air time.
UrbanScene3D: A Large Scale Urban Scene Dataset and Simulator
With rapid development in UAV technologies, it is now possible to reconstruct large-scale outdoor scenes using only images captured by low-cost drones. The problem, however, becomes how to plan the aerial path for a drone to capture images so that two conflicting goals are optimized: maximizing the reconstruction quality and minimizing mid-air image acquisition effort. Existing approaches either resort to pre-defined dense and thus inefficient view sampling strategy, or plan the path adaptively but require two onsite flight passes and intensive computation in-between. Hence, using these methods to capture and reconstruct large-scale scenes can be tedious. In this paper, we present an adaptive aerial path planning algorithm that can be done before the site visit. Using only a 2D map and a satellite image of the to-be-reconstructed area, we first compute a coarse 2.5D model for the scene based on the relationship between buildings and their shadows. A novel Max-Min optimization is then proposed to select a minimal set of viewpoints that maximizes the reconstructability under the the same number of viewpoints. Experimental results on benchmark show that our planning approach can effectively reduce the number of viewpoints needed than the previous state-of-the-art method, while maintaining comparable reconstruction quality. Since no field computation or a second visit is needed, and the view number is also minimized, our approach significantly reduces the time required in the field as well as the off-line computation cost for multi-view stereo reconstruction, making it possible to reconstruct a large-scale urban scene in a short time with moderate effort.
VGF-Net: Visual-Geometric Fusion Learning for Simultaneous Drone Navigation and Height Mapping
The drone navigation requires the comprehensive understanding of both visual and geometric information in the 3D world. In this paper, we present a Visual-Geometric Fusion Network (VGF-Net), a deep network for the fusion analysis of visual/geometric data and the construction of 2.5D height maps for simultaneous drone navigation in novel environments. Given an initial rough height map and a sequence of RGB images, our VGF-Net extracts the visual information of the scene, along with a sparse set of 3D keypoints that capture the geometric relationship between objects in the scene. Driven by the data, VGF-Net adaptively fuses visual and geometric information, forming a unified Visual-Geometric Representation. This representation is fed to a new Directional Attention Model (DAM), which helps enhance the visual-geometric object relationship and propagates the informative data to dynamically refine the height map and the corresponding keypoints. An entire end-to-end information fusion and mapping system is formed, demonstrating remarkable robustness and high accuracy on the autonomous drone navigation across complex indoor and large-scale outdoor scenes.

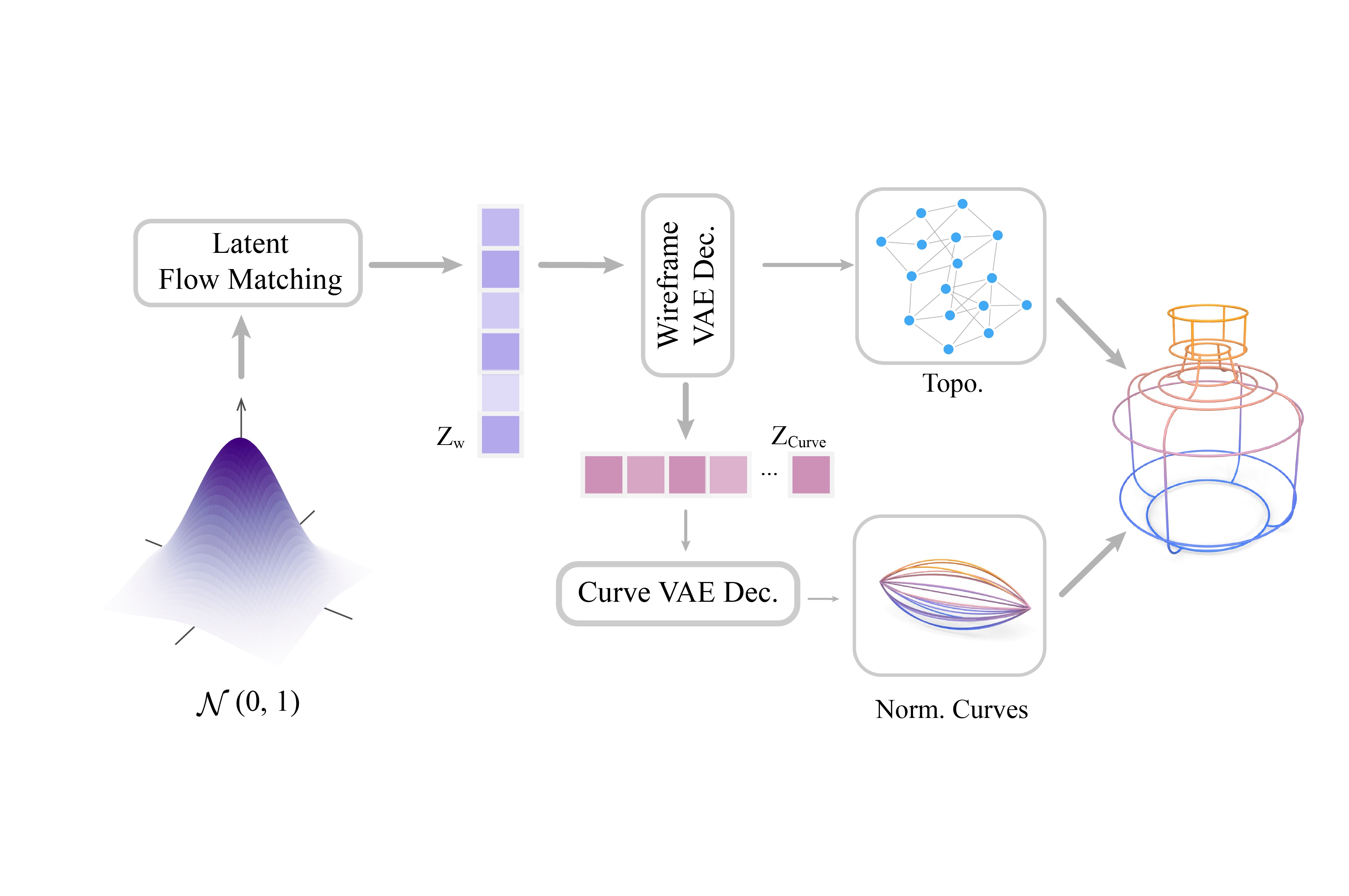 CLR-Wire: Towards Continuous Latent Representations for 3D Curve Wireframe GenerationIn Proc. SIGGRAPH , 2025
CLR-Wire: Towards Continuous Latent Representations for 3D Curve Wireframe GenerationIn Proc. SIGGRAPH , 2025 UrbanScene3D: A Large Scale Urban Scene Dataset and SimulatorGraphic Open Source Dataset Award, 2021
UrbanScene3D: A Large Scale Urban Scene Dataset and SimulatorGraphic Open Source Dataset Award, 2021











